

本文较长,建议点赞收藏,以免遗失。
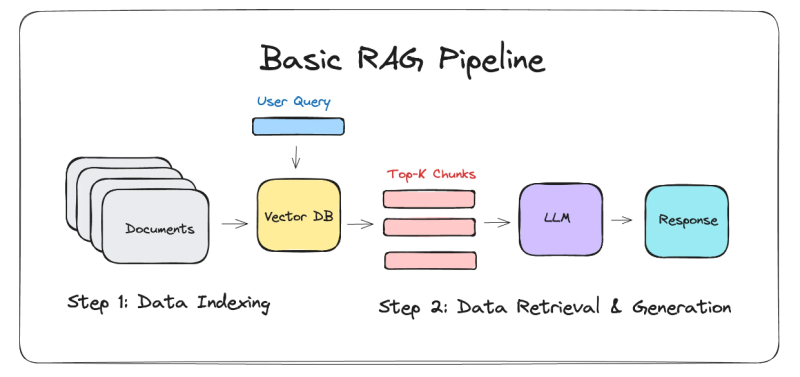
一、机器学习基础:监督vs无监督学习
监督学习通过带标签数据训练预测模型,核心是学习输入到输出的映射关系:
# 监督学习示例:线性回归
import numpy as np
from sklearn.linear_model import LinearRegression
# 生成数据:y = 2x + 1 + 噪声
X = np.array([[1], [2], [3], [4]])
y = np.array([2.9, 5.1, 7.2, 8.8])
# 创建并训练模型
model = LinearRegression()
model.fit(X, y)
# 预测新数据
print(f"x=5时预测值: {model.predict([[5]])[0]:.2f}") # 输出:10.95无监督学习发现数据内在结构,无需标签指导:
# 无监督学习示例:K-means聚类
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 生成模拟客户数据:年龄 vs 消费金额
data = np.array([[25, 3000], [30, 4500], [22, 2500],
[45, 8000], [50, 9500], [60, 12000]])
# 聚类分析
kmeans = KMeans(n_clusters=2)
kmeans.fit(data)
# 可视化结果
plt.scatter(data[:,0], data[:,1], c=kmeans.labels_, cmap='viridis')
plt.xlabel('年龄')
plt.ylabel('月消费(元)')
plt.title('客户消费行为聚类')
plt.show()二、过拟合与欠拟合:模型泛化诊断
模型复杂度与泛化能力关系:
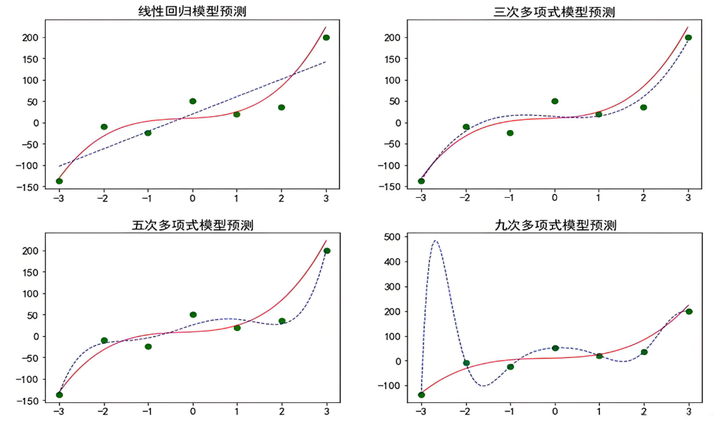
实用解决方案:
欠拟合对策:
-
- 增加特征工程(多项式特征、交叉特征)
- 使用更复杂模型(决策树→随机森林)
- 延长训练时间(深度学习)
过拟合对策:
-
- 正则化技术(L1/L2正则化)
# L2正则化示例
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=0.5) # 正则化强度
ridge.fit(X, y)- 早停法(监控验证集性能)
- Dropout(神经网络专用)
三、偏差-方差分解:误差本质解析
数学本质:
![图片[2]-AI大模型应用开发工程师必备机器学习核心概念深度解析与实践指南-深渡AI-智启未来](https://pica.zhimg.com/v2-270413c9b5ab405b8db3dc05eee38032_1440w.jpg)
靶心图解析:
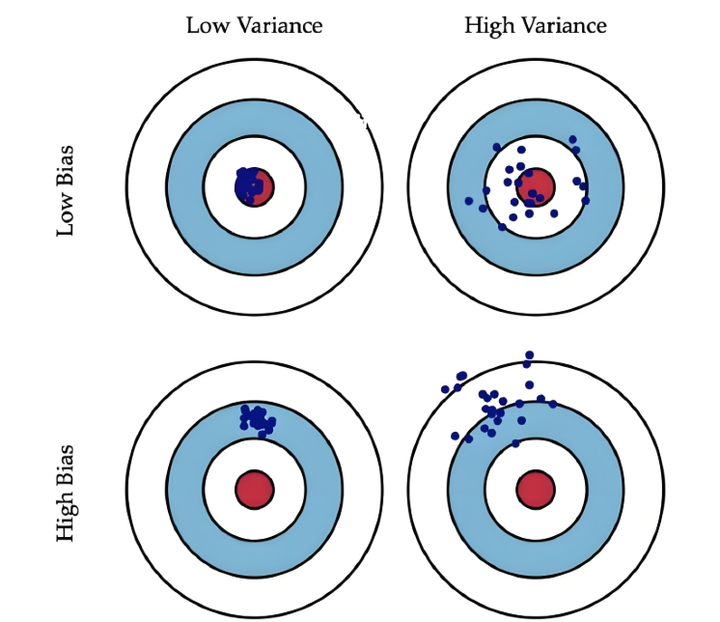
调优策略:

四、模型评估指标全景图
分类任务评估矩阵:
# 多维度评估示例
from sklearn.metrics import precision_recall_curve, roc_curve
# 精确率-召回率曲线
precision, recall, _ = precision_recall_curve(y_true, y_pred)
plt.plot(recall, precision)
plt.title('P-R曲线')
# ROC曲线
fpr, tpr, _ = roc_curve(y_true, y_pred)
plt.plot(fpr, tpr)
plt.title('ROC曲线')回归任务指标对比:

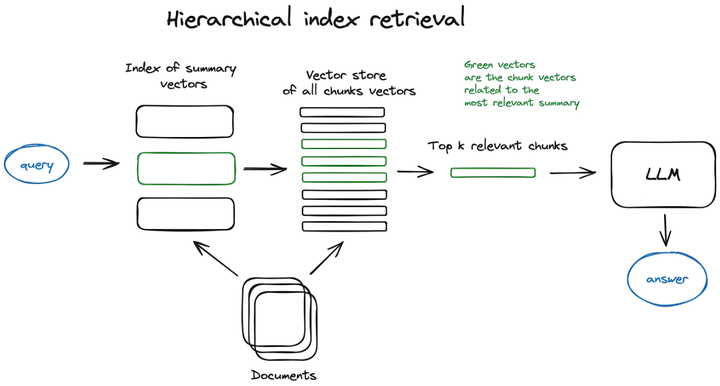
五、交叉验证:模型验证的黄金标准
K折交叉验证流程:
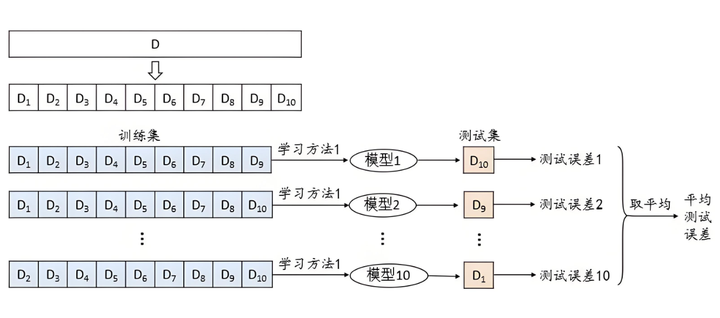
进阶交叉验证技术:
# 分层K折交叉验证
from sklearn.model_selection import StratifiedKFold
from sklearn.ensemble import RandomForestClassifier
# 创建分层交叉验证器
stratified_cv = StratifiedKFold(n_splits=5, shuffle=True)
# 超参数网格搜索
param_grid = {'n_estimators': [50, 100, 200],
'max_depth': [None, 5, 10]}
grid_search = GridSearchCV(
RandomForestClassifier(),
param_grid,
cv=stratified_cv,
scoring='f1_macro'
)
grid_search.fit(X, y)
print(f"最优参数: {grid_search.best_params_}")交叉验证类型对比表:
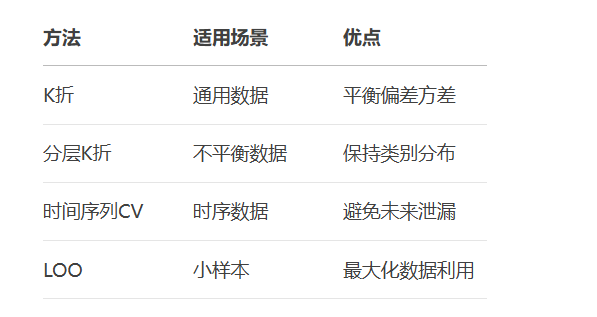
六、实战案例:乳腺癌诊断模型
端到端建模流程:
# 完整机器学习流程
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import roc_auc_score, confusion_matrix
import seaborn as sns
# 数据加载与探索
data = load_breast_cancer()
X, y = data.data, data.target
print(f"特征数: {X.shape[1]}, 样本数: {X.shape[0]}")
# 数据预处理
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler().fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 模型训练与调优
param_grid = {'C': [0.1, 1, 10], 'gamma': [0.01, 0.1, 1]}
grid = GridSearchCV(SVC(probability=True, kernel='rbf'), param_grid, cv=5)
grid.fit(X_train_scaled, y_train)
# 模型评估
best_model = grid.best_estimator_
probs = best_model.predict_proba(X_test_scaled)[:, 1]
print(f"测试集AUC: {roc_auc_score(y_test, probs):.4f}")
# 混淆矩阵可视化
cm = confusion_matrix(y_test, best_model.predict(X_test_scaled))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title('混淆矩阵')七、学习路线图与资源推荐
分阶段学习路径:
graph TD
A[数学基础] -->|线性代数/概率论| B[编程能力]
B -->|Python/NumPy/Pandas| C[机器学习理论]
C -->|SKLearn实践| D[特征工程]
D --> E[模型调优]
E --> F[深度学习]通过本指南,你已建立机器学习核心知识框架。下一步建议选择医疗诊断、金融风控或推荐系统等垂直领域进行专项突破,将理论转化为解决实际问题的能力!
© 版权声明
THE END



暂无评论内容